
Numpy
# Numpy
import numpy as np
# 数据类型
numpy中可以有如下数据类型 可以接收list,tuple
| 类型 | 描述 |
|---|---|
| bool | 用1位存储的布尔类型(值为TRUE或FALSE) |
| int | 由所在平台决定其精度的整数(一般为int32或int64)int8 1字节整数 |
| int16 | 2字节整数int32 4字节整数int64 8字节整数 |
| uint8 | 1字节无符号整数 |
| uint16 | 2字节无符号整数uint324字节无符号整数uint648字节无符号整数 |
| float16 | 半精度浮点数(16位),1位符号,5位指数,10位尾数 |
| float32 | 单精度浮点数(32位),1位符号,8位指数,23位尾数 |
| float64/float | 双精度浮点数(64位),1位符号,11位指数,52位尾数 |
| complex64 | 复数,分别用32位表示实部和虚部 |
| complex128/complex | 复数,分别用64位表示实部和虚部 |
# 创建数组
数组的元素类型必须相同,且初始化之后就无法修改类型!可以通过a.astype(np.float)生成指定类型新数组
np.array()- np.array([[数组],[数组]],dtype=np.表中数据类型)
- 默认元素类型为int32,可以使用dtype指定
np.arange(n)- np.arange(x,y,dtype=np.表中数据类型)
- 创建从x到y的一维数组。默认从0开始
np.linspace(x,y,n,endpoint=True)- 从x到y生成n个等距离浮点数一维数组
- endpoint默认True
np.zeros((x,y))/np.ones((x,y))- 生成x行y列的全0/1数组
np.zeros_like(size)/np.ones_like(size)- 生成规模为size的全0/1数组,想要创造和其他数组规模一致的全0-1数组使用
np.full((x,y),n)/np.empty((x,y))- 生成x行y列的全n/随机未初始化数组
np.full_like(array,n)- 生成和array规模一致的全n数组
np.identity(n)- 生成和对角线为1的n*n数组
np.diag([一维数组],k=0)- 把以一维数组作为对角线k为偏移生成数组。规模由一维数组决定
np.eye(x,y,k=0,dtype=np.int)- 生成x行y列的数组
- 默认情况下输出的是对角线全1,其余全0的方阵,如果k为正整数,则在右上方第k条对角线全1其余全0,k为负整数则在左下方第k条对角线全1其余全0。
numpy.asarray(iterable, dtype = None, order = None)- 传入列表, 列表的元组, 元组, 元组的元组, 元组的列表,多维数组,指定类型和行列优先("C","F")
numpy.fromiter(iterable, dtype, count=-1)- 传入可迭代对象,默认-1数据全部读取
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)- 生成数列之后取㏒对数,底默认为10
- start 序列的起始值
- stop 序列的终止值为
- num 要生成的等步长的样本数量,默认为50
- endpoint 该值为 ture 时,数列中中包含stop值,反之不包含,默认是True。
- base 对数 log 的底数
- dtype ndarray 的数据类型
Click to See More Code
import numpy as np
a=np.array([1,2,3])#从序列生成数组
b=np.arange(1,10,2,dtype=np.float32)#顺序生成数组默认0,步长为2,有头没尾
c=np.linspace(1,10,8,endpoint=True)#1到10生成8个等距float,默认有尾
d=np.zeros((3,3))#x行y列的0数组
e=np.ones((4,5))#x行y列的1数组
f=np.full((4,5),7)#按照给定维度填充n生成的数组
g=np.empty((5,7))#随机未初始化的5行7列的空数组
h=np.eye(5,5,k=1,dtype=np.float)#x行y列,k默认为0全1对角线在中间。
x=(1,2,3,4,7,5,3,12)
i=np.asarray(x,dtype=np.float16,)#和np.array一样,不过可以用于迭代对象
j=np.logspace(1,16,num=10,endpoint=True, base=10.0)
Click to See More Results
a : [1 2 3]
b : [1. 3. 5. 7. 9.]
c : [ 1. 2.28571429 3.57142857 4.85714286 6.14285714 7.42857143
8.71428571 10. ]
d : [[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
e : [[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]]
f : [[7 7 7 7 7]
[7 7 7 7 7]
[7 7 7 7 7]
[7 7 7 7 7]]
g : [[ 0.00000000e+000 6.95302574e-310 1.19563886e-321 nan
2.97400229e+222 2.31261091e-152 9.16526748e+242]
[ 5.22864484e-067 -1.07080412e-237 -5.74085429e-208 -2.95588219e+191
9.16526748e+242 7.97805968e-072 6.32300962e+233]
[ 5.38210304e+228 -2.84647293e+198 -1.52258944e-156 -4.01320607e-020
9.66537616e-070 -3.50225744e-015 2.28638615e-074]
[-4.09008785e-203 -2.58641119e-247 -1.72482363e-063 6.32301179e+233
7.92680158e-061 6.74108423e+199 6.90383683e-072]
[ 6.12271013e+223 2.33365045e+030 -2.77780087e+179 -2.14709960e+186
-1.48714169e-087 2.20892736e+161 1.32211967e-320]]
h : [[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0.]]
i : [ 1. 2. 3. 4. 7. 5. 3. 12.]
j : [1.00000000e+01 4.64158883e+02 2.15443469e+04 1.00000000e+06
4.64158883e+07 2.15443469e+09 1.00000000e+11 4.64158883e+12
2.15443469e+14 1.00000000e+16]
# 从外部读取
# Random的数据分布
np.random.random((2,3))- np.rand()
- 2(x)行3(y)列的0-1之间的随机浮点数
np.random.randint(0,10,(3,2))- 给定size和范围的随机整数,有头没尾(直接+1不就有尾了🤔
- random_integers和这个一样不过这个是有头有尾的(已不推荐使用)
- 0-10之间的两行三列的随机整数
np.random.randn(size)- 产生给定siez大小的正态分布样本组成的数组,直接调用返回一个数
np.random.random((2,3))- 2(x)行3(y)列的0-1之间的随机浮点数
random.randrange(start, stop, step)- 返回以start开始,stop结束,step为步长的列表中的随机整数,三个参数均为整数(或者小数位为0),若start大于stop时 ,setp必须为负数.step不能是0.
- random.uniform(n1, n2)
- 接受两个数字参数,返回两个数字区间的一个浮点数,不要求val1小于等于val2
np.random.choice(x,(size))- 从x一维数组中随机选数组成给定size的数组
np.random.shuffle(f)- 对自身起作用,只能这样调用
- np.random.permutation(f)效果相同不过不对自身起作用而是返回
- 打乱数组
np.random.seed(5)- seed(n)设置随机数种子值,默认系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同
- 在设置种子之后,本次程序运行使用random产生随机数的时候会根据这个值来产生
numpy.random.normal(loc=0.0, scale=1.0, size=None)- loc:float此概率分布的均值(对应着整个分布的中心centre)
- scale:float此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
- 正态分布,np.random.randn使用标准正态分布(μ=0,σ=1)也就是默认参数
.7dc06e85.svg)
Click to See More Code
a=np.random.random(10)#产生给定siez大小的0-1随机数组
b=np.random.rand(10)#等价于random
c=np.random.randn(5)#产生给定siez大小的正态分布样本组成的数组,直接调用返回一个数
d=np.random.randint(1,10,(2,3))
x=np.array([8,8,7,7])
e=np.random.choice(x,(3,4))#从数组里随机选取
f=np.arange(1,11,2)
g=np.random.permutation(f)#返回一个打乱的
np.random.shuffle(f)#对自身起作用,只能这样调用
num=0
np.random.seed(5)
while(num<5):
print((np.random.random(),np.random.random()))
num+=1
np.random.seed(5)
print((np.random.random(),np.random.random()))
print((np.random.random(),np.random.random()))
print((np.random.random(),np.random.random()))
for k,v in {'a':a,'b':b,'c':c,'d':d,'e':e,'f':f,'g':g,'h':h,'i':i,'j':j}.items():
print(k,":",v,'\n')
Click to See More Results
(0.22199317108973948, 0.8707323061773764)
(0.20671915533942642, 0.9186109079379216)
(0.48841118879482914, 0.6117438629026457)
(0.7659078564803156, 0.5184179878729432)
(0.29680050157622195, 0.18772122866125163)
(0.22199317108973948, 0.8707323061773764)
(0.20671915533942642, 0.9186109079379216)
(0.48841118879482914, 0.6117438629026457)
a : [0.20671916 0.91861091 0.48841119 0.61174386 0.76590786 0.51841799
0.2968005 0.18772123 0.08074127 0.7384403 ]
b : [0.44130922 0.15830987 0.87993703 0.27408646 0.41423502 0.29607993
0.62878791 0.57983781 0.5999292 0.26581912]
c : [-0.98060789 -0.85685315 -0.87187918 -0.42250793 0.99643983]
d : [[4 2 8]
[4 2 6]]
e : [[7 8 7 7]
[7 7 8 7]
[7 8 8 7]]
f : [3 5 9 1 7]
g : [5 9 3 1 7]
h : [[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0.]]
i : [ 1. 2. 3. 4. 7. 5. 3. 12.]
j : [1.00000000e+01 4.64158883e+02 2.15443469e+04 1.00000000e+06
4.64158883e+07 2.15443469e+09 1.00000000e+11 4.64158883e+12
2.15443469e+14 1.00000000e+16]
# 数组的属性
属性不是函数;NumPy 数组的维数称为秩(rank),一维数组的秩为 1,二维数组的秩为 2,以此类推。在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)
ndarray.ndim秩,即轴的数量或维度的数量ndarray.shape数组的维度,对于数组,n 行 m 列ndarray.size数组元素的总个数,相当于 .shape 中 n*m 的值ndarray.dtypendarray 对象的元素类型ndarray.itemsizendarray 对象中每个元素的大小,以字节为单位ndarray.flagsndarray 对象的内存信息ndarray.realndarray元素的实部ndarray.imagndarray 元素的虚部
Click to See More Code
a=np.array([1,4,5,7,3,2,3,5,7,6,4,2,2]dtype=np.float16).reshap()
#---结果---
a.ndim: 2
a.shape: (2, 6)
a.dtype: float16
a.size: 12
a.itemsize: 2
a.flags: C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : False
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
a.real: [[1. 4. 5. 7. 3. 2.]
[3. 5. 7. 6. 4. 2.]]
a.imag: [[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]]
自定义类型
可以使用自定义类型的np,不过有这功夫为啥不去用pandas
np.dtype([('book','S40'),('version',np.int)])
mytype=np.dtype({"names":['book','version'],'formats':['S40',np.int]})
mytype=np.dtype([('book','S40'),('version',np.int)])#这样定义更习惯一些
mybook=np.array([('a',1),('b',2)],dtype=mytype)
mybook['book']
mybook['book'][0]
#---结果---
mytype: [('book', 'S40'), ('version', '<i4')]
mybook: [(b'a', 1) (b'b', 2)]
mybook["book"]: [b'a' b'b']
mybook["book"][0]: b'a'
# 四则运算
定义数组
a=np.array([1,2,3,4])
b=np.array([10,20,30,40])
加减,次方,相乘,每一项都分别相乘,乘数字也是一样的
- a+b->[11 22 33 44]
- a**2->[ 1 4 9 16]
- a*b->[ 10 40 90 160]
TIP
数组相乘用np.dot(a,b) or a.dot(b),下面在数组会说到
把每一项都做sin操作,把每一项都求sin,cos,tan,cot同理
- x=np.sin(a)
比较,返回一个同等规模的数组,该数组的项为每一项进行比较操作之后的结果,满足就为Ture,不满足就False
- x=(b<30)
- 支持与(and)或(or)非(not)
数组相乘的两种方法
- np.dot(a1,b1)==a1.dot(b1)
求一个数组所有元素的
x=np.max(a)最大x=np.min(a)最小x=np.sum(a)和
分别对行/列(用axis控制1行0列)求最大值最小值求和
x=np.max(a,axis=1)对行求最大x=np.min(a,axis=0)对列求最小x=np.sum(a,axis=0)对列求和
判等
- (a==b).all()
- 直接使用(a==b)是个同规模TorF数组,需要使用all
- np.any(a,axis=None,out=None)
- a是类数组对象,只要a中(或者某个指定的轴中)有一个元素是True,则返回True,否则返回False。
- array.any()可以直接调用
- np all(a,axis=None,out=None)
- 如果类数组对象a(或者某个指定的轴中)所有元素都是True,则返回True,否则返回False。
- array.all()可以直接调用
忘记的
x=power(2,10)2的10次方
out 参数可以指定保存在哪个变量里
m=np.empty_like(a)
np.any(a,b,out=m)
自定义处理函数
可以自定义处理函数,对每个值进行处理np.frompyfunc(func,nin,nout)func函数名字,nin接受几个参数,nout返回几个对象
import numpy as np
def a(x,y):
return (x+y)/(x-y)
x=np.arange(1,11)
y=np.random.uniform(1,100,(10,))
myfun=np.frompyfunc(a,2,1)
myfun(x,y)
Click to See More Results
array([-1.0313295805710363, -1.0912359523752801, -3.1601351032809557,
-1.1439328568074587, -1.2993873174977089, -1.2692649558730051,
-1.1620112787552441, -1.6895206519886756, -1.3278806829928869,
-1.8810816890174227], dtype=object)
| 函数 | 作用 |
|---|---|
| np.sin,np.cos,np.tan | 三角函数 |
| np.arcsin,np,arccos,np.arctan | 反三角函数 |
| np.sinh,np.cosh,np.tanh | 双曲三角函数 |
| np.arcsinh,np,arccosh,np.arctanh | 反双曲三角函数 |
| np.sqrt | 求平方根 |
| np.exp | 自然指数 |
| np.log,np.log2,np.log10 | 计算对数底数e,2,10 |
| 函数 | 作用 |
|---|---|
| np.add,np.subtract,np.multiply,np.divide | 加减乘除 |
| np.equal,np.not_equal,np.less, np.less_equal,np.greater,np.greater_equal | 等于,不等鱼,小鱼,小鱼等鱼,大鱼,大鱼等于 |
| np.power,np.remainder,np.reciprocal | 指数,余数,倒数运算(不要用整数) |
| np.real,np.imag,np.conj | 实部,虚部,复数 |
| np.sing,np.abs | 得到符号,得到绝对值 |
| np.floor,np.ceil,np.rint | 三个都是取整 |
| np.round | 四舍五入 |
| 函数 | 作用 |
|---|---|
| np.mean,np.average | 均值,加权均值 |
| np.var,np.std | 方差标准差 |
| np.max,np.min | 最大最小值 |
| np.argmix,np.argmin | 最大最小值的索引 |
| np.ptp | 全距,最大最小值的差 |
| np.percentile | 百分位在统计对象中的值?? |
| np.median | 中值 |
| np.sum | 求和 |
字符串处理函数
| 函数 | 作用 |
|---|---|
| np.char.add() | 对两个数组的逐个字符串元素进行连接 |
| np.char.multiply() | 返回按元素多重连接后的字符串 |
| np.char.center() | 居中字符串 |
| np.char.capitalize() | 将字符串第一个字母转换为大写 |
| np.char.title() | 将字符串的每个单词的第一个字母转换为大写 |
| np.char.lower() | 数组元素转换为小写 |
| np.char.upper() | 数组元素转换为大写 |
| np.char.split() | 指定分隔符对字符串进行分割,并返回数组列表 |
| np.char.splitlines() | 返回元素中的行列表,以换行符分割 |
| np.char.strip() | 移除元素开头或者结尾处的特定字符 |
| np.char.join() | 通过指定分隔符来连接数组中的元素 |
| np.char.replace() | 使用新字符串替换字符串中的所有子字符串 |
| np.char.decode() | 数组元素依次调用str.decode |
| np.char.encode() | 数组元素依次调用str.encode |
# 排序搜索计数
排序函数
- np.sort(a, axis, kind='quicksort', order)
- axis不填就变一维
- order可以指定排序字段,在自定义数据结构时用
| 名称 | 速度 | 时间复杂度 | 工作空间 | 稳定性 |
|---|---|---|---|---|
| 'quicksort'(快速排序) | 1 | O(n^2) | 0 | 否 |
| 'mergesort'(归并排序) | 2 | O(n*log(n)) | ~n/2 | 是 |
| 'heapsort'(堆排序) | 3 | O(n*log(n)) | 0 | 否 |
- np.argsort(x)
- 返回数组从小到大的索引值
- x=np.array([2,4,5,3,-10,1]);np.argsort(x) :[4 5 0 3 1 2]
TIP
argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引号)
例如:x[4]=-10最小,所以y[0]=4,
同理:x[2]=5最大,所以y[5]=2
- np.lexsort(x)
- 多数组排序,等用到再看吧。
x = np.linspace(3, 9, 100).reshape(10,10)
np.random.shuffle(x)
np.sort(x,axis=1,kind='heapsort')
------------------------------------------------
x=np.arange(0,32).reshape(2,4,4)
np.random.shuffle(x[0,3,...])
np.random.shuffle(x[1,...,0])
x,np.argsort(x[0])
------------------------------------------------
Click to See More Results
array([[6.03030303, 6.09090909, 6.15151515, 6.21212121, 6.27272727,
6.33333333, 6.39393939, 6.45454545, 6.51515152, 6.57575758],
[8.45454545, 8.51515152, 8.57575758, 8.63636364, 8.6969697 ,
8.75757576, 8.81818182, 8.87878788, 8.93939394, 9. ],
[4.21212121, 4.27272727, 4.33333333, 4.39393939, 4.45454545,
4.51515152, 4.57575758, 4.63636364, 4.6969697 , 4.75757576],
[7.24242424, 7.3030303 , 7.36363636, 7.42424242, 7.48484848,
7.54545455, 7.60606061, 7.66666667, 7.72727273, 7.78787879],
[4.81818182, 4.87878788, 4.93939394, 5. , 5.06060606,
5.12121212, 5.18181818, 5.24242424, 5.3030303 , 5.36363636],
[6.63636364, 6.6969697 , 6.75757576, 6.81818182, 6.87878788,
6.93939394, 7. , 7.06060606, 7.12121212, 7.18181818],
[7.84848485, 7.90909091, 7.96969697, 8.03030303, 8.09090909,
8.15151515, 8.21212121, 8.27272727, 8.33333333, 8.39393939],
[5.42424242, 5.48484848, 5.54545455, 5.60606061, 5.66666667,
5.72727273, 5.78787879, 5.84848485, 5.90909091, 5.96969697],
[3. , 3.06060606, 3.12121212, 3.18181818, 3.24242424,
3.3030303 , 3.36363636, 3.42424242, 3.48484848, 3.54545455],
[3.60606061, 3.66666667, 3.72727273, 3.78787879, 3.84848485,
3.90909091, 3.96969697, 4.03030303, 4.09090909, 4.15151515]])
-----------------------------------------------------------------
x:array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[13, 12, 15, 14]],
[[20, 17, 18, 19],
[28, 21, 22, 23],
[16, 25, 26, 27],
[24, 29, 30, 31]]]),
x,np.argsort(x[0]):
array([[0, 1, 2, 3],
[0, 1, 2, 3],
[0, 1, 2, 3],
[1, 0, 3, 2]], dtype=int64)
搜索处理函数
- np.where(condition, [x, y])
- 满足condition就返回x,不满足就返回y
- 没给x,y只给了condition就返回满足condition的元素坐标,返回元组套array,维度应该满足原数组的维度。
- np.nonzero(a)返回非零元素的的索引,速度约为你自己写的1.6倍😶
- np.extract(condition,x)可以直接把元素抽出来变成一维数组
- np.select(conditionlist,choicelist,default=0)
- 多条件筛选,数组可以输入多个,条件也可以有多个,支持与或非,看官网例子
- np.choose(a, choices, out=None, mode='raise')
- 接受一个int型数组a
- 默认raise,
- np.piecewise(x, cond, func)
- 你可以把她想像成一个map函数,嗯就这样
- 和select一个用法,见下例
- np.choose(x,[n1,n2....])
- 具体干嘛用的,咱也不知道,咱也不敢问
- 其实是做映射用的,x中的数值会被一一映射为n1,n2...所以元素种类个数一定要相同
- argmax(a)和argmin(a)
- 返回最大值和最小值的下标。如果不指定axis,就返回一维化之后的数组下标。
- np.nanargmin(a, axis=None)这个可以无视NaN,最大值也同样
- np.argmax(np.bincount(a))找出a中出现最多的元素
a=np.random.randint(1,10,5)
np.where(a>3,"xxx",1) # 1
a = np.random.randint(1,100,8).reshape(2,2,2)
b=np.where(a>4) # 2
np.extract(a>4,a)
------------------------------------------------
x = np.arange(10)
condlist = [x<3, x>5]
choicelist = [x, x**2]
np.select(condlist, choicelist)
------------------------------------------------
x = np.linspace(3, 9, 100)
cond = [x < 3, (3 <= x) & (x <= 9), x > 9]
func = [0, lambda x : (x - 3) / (9 - 3), 1]
np.piecewise(x, cond, func)
------------------------------------------------
a=np.array([3,4,6,3,3,3,3,3,3,3,45,12,2,1,1,23])
np.argmax(np.bincount(a))
------------------------------------------------
Click to See More Results
array(['xxx', 'xxx', 'xxx', '1', '1'], dtype='<U11') #1
(array([[[ 1, 97], # 2
[14, 97]],
[[70, 60],
[41, 63]]])
(array([0, 0, 0, 1, 1, 1, 1], dtype=int64),
array([0, 1, 1, 0, 0, 1, 1], dtype=int64),
array([1, 0, 1, 0, 1, 0, 1], dtype=int64)))
array([33, 10, 48, 92, 91, 90, 59, 97]))
--------------------------------------------------
array([ 0, 1, 2, 0, 0, 0, 36, 49, 64, 81]
--------------------------------------------------
array([0. , 0.01010101, 0.02020202, 0.03030303, 0.04040404,
0.05050505, 0.06060606, 0.07070707, 0.08080808, 0.09090909,
0.1010101 , 0.11111111, 0.12121212, 0.13131313, 0.14141414,
0.15151515, 0.16161616, 0.17171717, 0.18181818, 0.19191919,
0.2020202 , 0.21212121, 0.22222222, 0.23232323, 0.24242424,
0.25252525, 0.26262626, 0.27272727, 0.28282828, 0.29292929,
0.3030303 , 0.31313131, 0.32323232, 0.33333333, 0.34343434,
0.35353535, 0.36363636, 0.37373737, 0.38383838, 0.39393939,
0.4040404 , 0.41414141, 0.42424242, 0.43434343, 0.44444444,
0.45454545, 0.46464646, 0.47474747, 0.48484848, 0.49494949,
0.50505051, 0.51515152, 0.52525253, 0.53535354, 0.54545455,
0.55555556, 0.56565657, 0.57575758, 0.58585859, 0.5959596 ,
0.60606061, 0.61616162, 0.62626263, 0.63636364, 0.64646465,
0.65656566, 0.66666667, 0.67676768, 0.68686869, 0.6969697 ,
0.70707071, 0.71717172, 0.72727273, 0.73737374, 0.74747475,
0.75757576, 0.76767677, 0.77777778, 0.78787879, 0.7979798 ,
0.80808081, 0.81818182, 0.82828283, 0.83838384, 0.84848485,
0.85858586, 0.86868687, 0.87878788, 0.88888889, 0.8989899 ,
0.90909091, 0.91919192, 0.92929293, 0.93939394, 0.94949495,
0.95959596, 0.96969697, 0.97979798, 0.98989899, 1. ])

计数
- np.isnan(arr).sum()
- 统计nan的个数
- count_nonzero(a[, axis])
- 统计非0元素个数
- np.unique(a,return_counts=True)
- 一维化,去重,统计元素出现次数
- np.argmax(np.bincount(line))
- 最大元素的坐标
import numpy as np
a=np.array([2,4,6,2,45,12,2,1,1,23]).reshape(2,5)
np.unique(a,return_counts=True)
结果:
((array([ 1, 2, 4, 6, 12, 23, 45]),
array([2, 3, 1, 1, 1, 1, 1], dtype=int64)),
-------------------------------------------------
a=np.array([0,7])
np.bincount(a)# 数字的出现次数,会从最大到最小先去重一遍,然后统计次数。
-------------------------------------------------
结果:array([1, 0, 0, 0, 0, 0, 0, 1], dtype=int64)分别是 最小0-7最大 每个数字的出现次数。
# 切片索引
np数组使用数组和轴描述数组的规模。维度从1开始算起,每增加一维嵌套就多一层。轴只是从0开始计数的数组,更符合计算机的计数习惯.切片和py中的list十分相似
x=a[开始:结束:步长]
逆序x[::-1]
切片还可以包括省略号…来使选择元组的长度与数组的维度相同,不过单次切片只能出现一次,这个地方还是有代码说服力强。
a=a.reshape(3,3)
y=np.arange(18).reshape(2,3,3)
y,y[1,...,:2]
#---结果---
y:
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]]])
y[1,...,:2]:
array([[ 9, 10],
[12, 13],
[15, 16]])
WARNING
数组 切片 得到的视图和原数组共享一个内存空间,修改会直接修改原数组的值。谨慎修改!
高维数组索引
获取数组中的元素,对于一维数组来说x[n]获取下标为n的元素。高维数组使用元组或者序列的方式取下标。娶不到最高维的时候就会直接取出该维度的列表
a=np.arange(9)
a,a[1]#一维数组取下标
a=a.reshape(3,3)
#高维数组三种取下标的方式
y=np.arange(18).reshape(2,3,3)
x = y[0,1,2],y[0,1,0]
#---结果---
a: [[0 1 2]
[3 4 5]
[6 7 8]]
a[0]: [0 1 2]
a[0][1]: 1
a[1,2]: 5
a[(1,2)]: 5
x:(5, 3)
花式索引(数组索引)
只用数组作为索引可以一次性取出多个值并组成列表。
x[[1,2,1]]->取出第0轴下标为1,2,1(重复就可以取出同样的元素)
WARNING
下标 取出的数组和原数组并没有共用一个内存空间,修改并不会互相影响
列表可以作为元组下标的一个元素,可配合元组下标使用
x[[1,2,1],[0,1,1]]->取出第0轴下标为1,2,1;取出第一轴下标为0,1,1的元素。
最后组成一个一维数组
布尔索引
布尔索引通过布尔运算(如:比较运算符)来获取符合指定条件的元素的数组。
还是使用上面的y,选出大于3的元素
y[y>3]->array([ 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17])
也可返回满足条件的同规模数组,判断是不是复数等
x=y>5
a = np.array([1, 2+6j, 5, 3.5+5j])
a[np.iscomplex(a)]
x:array([[[False, False, False],
[False, False, False],
[ True, True, True]],
[[ True, True, True],
[ True, True, True],
[ True, True, True]]])
a[np.iscomplex(a)]:[2.0+6.j 3.5+5.j]
# 数组操作
重新分配维度
x=l.reshape(3,2)3行两列- numpy.reshape(l, newshape, order='C')
a.resize(3,2)和reshap一样但不反回会直接改变原数组
c=np.arange(1,101,dtype=np.float32).reshape(-1,1,2)
#第0轴懒得数,第一轴1个元素,第二轴两个元素....
d=np.arange(1,101,dtype=np.float32).reshape(-1)
#弄成只有一个轴,数量不知道
e=np.arange(1,101,dtype=np.float32)
e.rsize(1,-1)
Click to See More Results
c: [(0)[(1)[(2) 1. 2.]]#注意第0 轴,第一轴,第二轴
[[ 3. 4.]]
[[ 5. 6.]]
[[ 7. 8.]]
[[ 9. 10.]]
[[ 11. 12.]]
[[ 13. 14.]]
[[ 15. 16.]]
[[ 17. 18.]]
[[ 19. 20.]]
[[ 21. 22.]]
[[ 23. 24.]]
[[ 25. 26.]]
[[ 27. 28.]]
[[ 29. 30.]]
[[ 31. 32.]]
[[ 33. 34.]]
[[ 35. 36.]]
[[ 37. 38.]]
[[ 39. 40.]]
[[ 41. 42.]]
[[ 43. 44.]]
[[ 45. 46.]]
[[ 47. 48.]]
[[ 49. 50.]]
[[ 51. 52.]]
[[ 53. 54.]]
[[ 55. 56.]]
[[ 57. 58.]]
[[ 59. 60.]]
[[ 61. 62.]]
[[ 63. 64.]]
[[ 65. 66.]]
[[ 67. 68.]]
[[ 69. 70.]]
[[ 71. 72.]]
[[ 73. 74.]]
[[ 75. 76.]]
[[ 77. 78.]]
[[ 79. 80.]]
[[ 81. 82.]]
[[ 83. 84.]]
[[ 85. 86.]]
[[ 87. 88.]]
[[ 89. 90.]]
[[ 91. 92.]]
[[ 93. 94.]]
[[ 95. 96.]]
[[ 97. 98.]]
[[ 99. 100.]]]
d: [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14.
15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28.
29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42.
43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56.
57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70.
71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84.
85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98.
99. 100.]
e: [[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14.
15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28.
29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42.
43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56.
57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70.
71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84.
85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98.
99. 100.]]
一维化原数组
x=a.ravel()x=a.flatten()会返回一维化数组而不会修改原数组
a=np.arange(1,11,dtype=np.float32).reshape(-1,1,2)#也是有头没尾注意
b=a.ravel()
Click to See More Results
a: [[[ 1. 2.]]
[[ 3. 4.]]
[[ 5. 6.]]
[[ 7. 8.]]
[[ 9. 10.]]]
b: [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
转置和高维数组转置
x=a.transpose()- np.transpose(x)
- 高维数组需要接受一个元组才能进行转置,回到transpose()这个函数,它里面就是维度的排序,比如我们后面写的transpose(2,1,0),就是把之前第三个维度转为第一个维度,之前的第二个维度不变,之前的第一个维度变为第三个维度
a.T- 对二维数组来说就是数组的转置
a=np.arange(1,11,dtype=np.float32).reshape(-1,1,2)#也是有头没尾注意
b=np.transpose(a)
c=a.T
Click to See More Results
a: [[[ 1. 2.]]
[[ 3. 4.]]
[[ 5. 6.]]
[[ 7. 8.]]
[[ 9. 10.]]]
b: [[[ 1. 3. 5. 7. 9.]]
[[ 2. 4. 6. 8. 10.]]]
c: [[[ 1. 3. 5. 7. 9.]]
[[ 2. 4. 6. 8. 10.]]]
轴交换&自然对数
x=a.swapaxes(x,y)x=a.exp(n)- exp,高等数学里以自然常数e=2.71828为底的指数函数
a=np.arange(1,11,dtype=np.float32).reshape(-1,1,2)
#也是有头没尾注意
b=a.swapaxes(2,1)
#交换2轴和1轴
c=a.transpose(0,2,1)
#第0轴还是第0轴,第一轴转到第二轴,第二轴转到第一轴,不能扔掉一个轴
d=np.exp(a)
e=np.exp(2)
#当是1的时候返回e
print('a:',a,"\nb:",b,'\nc:',c,'\nd:',d,'\ne:',e)
Click to See More Results
a: [[[ 1. 2.]]
[[ 3. 4.]]
[[ 5. 6.]]
[[ 7. 8.]]
[[ 9. 10.]]]
b: [[[ 1.]
[ 2.]]
[[ 3.]
[ 4.]]
[[ 5.]
[ 6.]]
[[ 7.]
[ 8.]]
[[ 9.]
[10.]]]
c: [[[ 1.]
[ 2.]]
[[ 3.]
[ 4.]]
[[ 5.]
[ 6.]]
[[ 7.]
[ 8.]]
[[ 9.]
[10.]]]
d: [[[2.7182817e+00 7.3890562e+00]]
[[2.0085537e+01 5.4598148e+01]]
[[1.4841316e+02 4.0342880e+02]]
[[1.0966332e+03 2.9809580e+03]]
[[8.1030840e+03 2.2026465e+04]]]
e: 7.38905609893065
# 合并拆分
水平组合:
x=np.arange(1,10)
y=np.arange(91,100,1)
np.hstack((y,x))# y在前
np.hstack((x,y))# y在后
效果等同于
np.concatenate((x,y),axis=1)
合并是有顺序的,hstack水平合并必须要第0轴的元素维度一致
垂直组合:
x=np.arange(1,10)
y=np.arange(91,100,1)
np.vstack((y,x))# y在前
np.vstack((x,y))# y在后
效果等同于
np.concatenate((x,y),axis=0)
合并也是有顺序的,vstack垂直合并必须第1轴的元素维度一致
水平 | 垂直 |
|---|
也可以直接调用 stack ,它的组合要求必须要有 相同的维度 ,你可以指定维度合并:
Click to See More Results
x=np.arange(1,10)
y=np.arange(91,100,1)
np.stack((x,y),axis=0)
np.stack((x,y),axis=1)
np.stack((x,y),axis=2)
axis=0:第0轴第一维最好理解,就只是简单的合并了两个原来的0轴。
array([[[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9]],
[[91, 92, 93],
[94, 95, 96],
[97, 98, 99]]])
axis=1:在第1轴,第二维合并,把第1轴的数组进行两两合并,维度也上升了
array([[[ 1, 2, 3],
[91, 92, 93]],
[[ 4, 5, 6],
[94, 95, 96]],
[[ 7, 8, 9],
[97, 98, 99]]])
axis=2:在第二轴(第三维)把每个元素进行合并,每个元素合并之后增加了一维
array([[[ 1, 91],
[ 2, 92],
[ 3, 93]],
[[ 4, 94],
[ 5, 95],
[ 6, 96]],
[[ 7, 97],
[ 8, 98],
[ 9, 99]]])
每个轴之间的合并规则了解一下,后面的以此类推了,二维数组用处最广泛。
深度组合
x=np.dstack((x,y))作用就是直接在第n轴进行组合(最高维)相当于np.stack((x,y),axis=n)
拆分
x=np.split(x,n or [n1,n2],axis=1 or 0 )
对x,指定第n或数个n1,n2 行 竖直 1,列 水平 0拆分
import numpy as np
x=np.linspace(1,10,20).reshape((4,5))
print(x)
x=np.split(x,[2,3],axis=1)#第2列,第3列后面分别进行拆分,拆成个数组😔
x
Click to See More Results
[[ 1. 1.47368421 1.94736842 2.42105263 2.89473684]
[ 3.36842105 3.84210526 4.31578947 4.78947368 5.26315789]
[ 5.73684211 6.21052632 6.68421053 7.15789474 7.63157895]
[ 8.10526316 8.57894737 9.05263158 9.52631579 10. ]]
[array([[1. , 1.47368421],
[3.36842105, 3.84210526],
[5.73684211, 6.21052632],
[8.10526316, 8.57894737]]),
array([[1.94736842],
[4.31578947],
[6.68421053],
[9.05263158]]),
array([[ 2.42105263, 2.89473684],
[ 4.78947368, 5.26315789],
[ 7.15789474, 7.63157895],
[ 9.52631579, 10. ]])]
np.hsplit()和vsplit()直接封装了axis的两个函数真贴心🐢
追加&插入&删除
x=np.append(a,b,axis=1 or 0)追加
x=np.delete(x,n or [n1,n2] ,axis=0)删除第n行/列
x=np.insert(x,n or [n1,n2],values,axis=1)在第n行/列处插入
x=np.array([[1. , 1.47368421],
[3.36842105, 3.84210526],
[5.73684211, 6.21052632],
[8.10526316, 8.57894737]])
values=[1,2]
np.append(x,[[1,2]],axis=0)
np.delete(x,2,axis=0)
np.insert(x,2,values,axis=0)
np.insert(x,[1,2],values,axis=0)
np.insert(x,[1,2],values,axis=1)
WARNING
注意insert多行列插入时的用法
Click to See More Results
np.append(x,[[1,2]],axis=0):
array([[1. , 1.47368421],
[3.36842105, 3.84210526],
[5.73684211, 6.21052632],
[8.10526316, 8.57894737],
[1. , 2. ]])
np.delete(x,2,axis=0):
array([[1. , 1.47368421],
[3.36842105, 3.84210526],
[8.10526316, 8.57894737]])
np.insert(x,2,values,axis=0):
array([[1. , 1.47368421],
[3.36842105, 3.84210526],
[1. , 2. ],
[5.73684211, 6.21052632],
[8.10526316, 8.57894737]])
np.insert(x,[1,2],values,axis=0):
array([[1. , 1.47368421],
[1. , 2. ],
[3.36842105, 3.84210526],
[1. , 2. ],
[5.73684211, 6.21052632],
[8.10526316, 8.57894737]])
np.insert(x,[1,2],values,axis=1):
array([[1. , 1. , 1.47368421, 2. ],
[3.36842105, 1. , 3.84210526, 2. ],
[5.73684211, 1. , 6.21052632, 2. ],
[8.10526316, 1. , 8.57894737, 2. ]])
# 广播机制
两数组规模(形状)相同的话会对应相乘,如果不同自动触发广播
insert函数那里就触发了广播,官方给的说法是:
- 让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在前面加1补齐
- 输出数组的shape是输入数组shape的各个轴上的最大值
- 如果输入数组的某个轴和输出数组的对应轴的长度相同或者其长度为1时,这个数组能够用来计算,否则出错
- 当输入数组的某个轴的长度为1时,沿着此轴运算时都用此轴上的第一组值
如果不看例子的话
🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔
🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔
🤔🤔🤔🤔🤔🙄🤔🤔🤔🤔🤔
🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔
🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔
官方给的例子,其实就是满足两个条件
- a不懂
- b不懂
Click to See More Code
Click to See More Results
# 副本和视图
字面意思,副本是在内存里完整的复制了一次,视图就参考sql里的视图概念(原理肯定不一样,会对原来的数据有影响。
副本和视图
Click to See More Results
# 线代矩阵
数学矩阵是线性代数里面的内容,不及格的回去复习。👻
创建矩阵使用np.mat(),np.matrix(),矩阵必须是二维的我们有时候也会直接把二维数组当作矩阵来处理。
- np.mat()
- 字符串创建
- 数组创建
- 矩阵为参数创建新矩阵
- 使用矩阵名字字符串参数创建矩阵
- np.matrix()
- 会直接创建一个copy变成matrix
- 其他用法参考mat
TIP
两个函数都会对传入的东西转为矩阵,但如果输入本身就是一个矩阵,则np.mat不会对该矩阵make a copy.仅仅是创建了一个新的引用。相当于np.matrix(data, copy = False)
创建和斐波那契
Click to See More Results
俩矩阵相乘的时候直接用*和np.dot()就一样了。矩阵运算和数组运算等效,并不会额外增加性能消耗。
矩阵是数组的子类,所有数组操作都对矩阵有效。矩阵在数学上不一定有逆但是在实践中可以直接求它的逆,如果没报错就有,报错了就没有逆。
转置 共轭 逆 秩
分别是T or np.getT(),H,I,np.linalg.matrix_rank(A)
上面的那几个
Click to See More Results
WARNING
在线性代数(math)中rank表示秩,但是必须明确的是在numpy里rank不是表示秩的概念,是表示维数的概念
对于一维的矩阵,array()array秩是1,mat()array秩是2(无论几维,返回的均是2)
np.asmatrix()<=>np.asarray()互相转换
# 矩阵的应用
矢量运算
矢量是相对于标量来说的。标量只有大小没有方向,矢量既有大小又有方向在numpy中用一维数组表示。np.array([a1,a2,a3,...]),有序。
矢量与标量之间的运算即标量与矢量的每一个数相乘。矢量之间的加减法就是每个元素之间对应加减
标量积和矢量积
又称内积点积,两矢量相乘的一种方式,结果为一标量 a·b=∑ (i-n)a1b1+a2b2+a3b3+···+anbn
TIP
其实np.dot()就是对一维数组进行标量积的计算
有np.inner(a,b),二维的时候内积如下
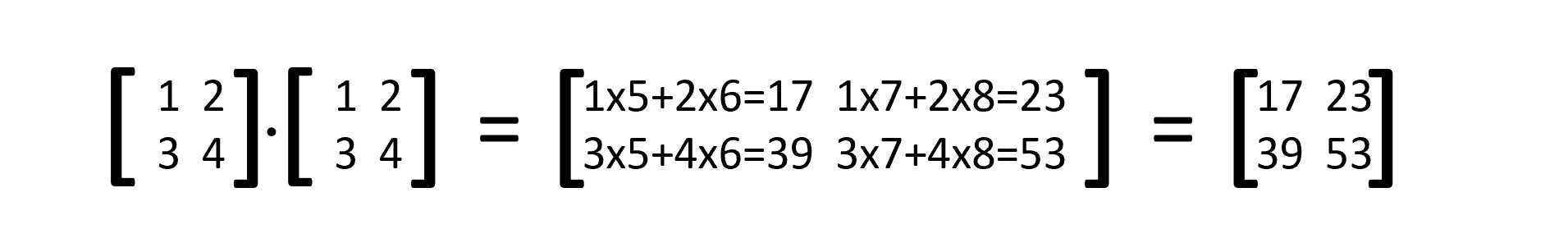
矢量积的运算由np.cross()运算三维的矢量积,运算规则如下图
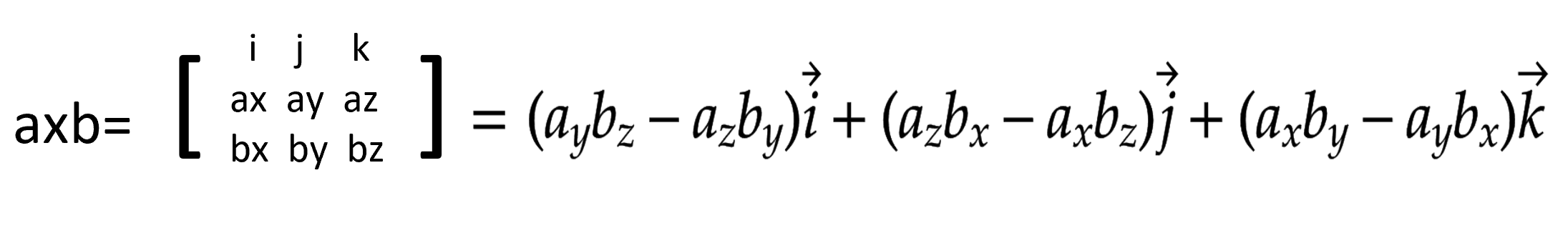
np.outer的用法
张量积
np.tensordot() 啥是张量积
多项式
np.ployld() 不同多项式之间可以进行加减乘除积分微积分运算,求根由根求多项式(一元二次三次方程怎么解来着),多项式拟合,都是支持的。
# Linear Algebra
np.linalg专门做线性代数的 解线性方程组
# 文件读写
numpy自己有个格式是npy文件
- load(),save()
- 默认数组是以未压缩的原始二进制格式保存在扩展名为 .npy 文件。
- savze()
- 将多个数组写入文件,默认数组以未压缩的原始二进制格式保存在 .npz 文件。
- loadtxt(),savetxt()
- 处理文本文件(.txt 等)
csv excel json
Click to See More Results
# Pandas
import pandas as pd
numpy pandas和Scipy+matplotlib无缝贴合,而且和后面的机器学习库也是配合精妙。
一直弄不完numpy,先不急着开坑
# Matplotlib
import matplotlib.pyplot as plt
Matplotlib允许我们配置绝大部分的东西,图片大小和分辨率(dpi)、线宽、颜色、风格、坐标轴、坐标轴以及网格的属性、文字与字体属性等。不过默认的已经够你玩的了很少用到,用到再去查就好。
# 最基本的图形
TIP
- 创建Figure对象----相当于一张画布;
- 用subplots()等函数创建分区----将画布分为若干个部分,也可以是一个部分;
- 在执行上一步的同时创建了Axes容器对象----相当于同时在分区上创建坐标系;
- Axes对象----坐标系的各个组成部分,可以被单独操作、设置;
- 在Axes 容器对象内绘图,保存
jupyter 使用
使用魔法命令在第一行 %matplotlib 运行一下,会出现一个RStudio的窗口,你所做的改动会实时的展现出来。
通过画一个最基本的图形看看使用pyplot的流程使用MATLAB风格
PS:如果你是在jupyter使用了上面的魔法命令,那就不用show
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(0, 2*np.pi, 0.01)//生成np数组
y = np.sin(x)//生成np数组
plt.plot(x, y)//生成plt
plt.show()//显示
生成一个pyplot对象plt,每一个程序文件只需要一个 plt.show()
中文和负号
matplotlib统一使用utf-8编码,所有的中文要在utf-8环境下显示,开头加入注释全局使用utf-8,设置默认字体。
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像时'-'显示为方块的问题
创建Figure对象
这东西类似于一张画布,fig=plt.figure() or实例化 plt.Figure()(一般不这样干
参数:
fig=figure(num=None, figsize=None, dpi=None, facecolor=None, edgecolor=None, frameon=True)
- num:图像编号或名称,数字为编号 ,字符串为名称
- figsize:指定figure的宽和高,单位为英寸;
- dpi 参数指定绘图对象的分辨率,即每英寸多少个像素,缺省值为80
- facecolor:背景颜色
- edgecolor:边框颜色
- frameon:是否显示边框
使用fig对象+面向对象风格画图
import numpy as np
import matplotlib.pyplot as plt
x=np.linspace(0,2*np.pi,100)
y1=np.sin(x)
y2=np.cos(x)
fig=plt.figure()
ax=fig.add_axes([0.1,0.1,0.8,0.8])
ax.plot(x,y2)
ax.plot(x,y1)
fig.savefig("x.png")#直接在程序目录下保存
plt函数和ax对象方法:
| plt函数 | ax对象方法 |
|---|---|
| plt.plot() | ax.plot() |
| plt.legend() | ax.legend() |
| plt.xlabel() | ax.set_xlabel() |
| plt.ylabel() | ax.set_ylabel() |
| plt.grid() | ax.grid() |
| plt.xlim() | ax.set_xlim() |
| plt.ylim() | ax.set_ylim() |
| plt.title() | ax.set_title() |
# 标题和坐标系
需要更高定制性参见matplotlib.ticker官方文档
plt.title(u'正弦曲线', fontdict={'size':20})- 设置标题
plt.xlabel(u'弧度', fontdict={'size':16})- 显示横轴名称
plt.ylabel(u'正弦值', fontdict={'size':16})- 显示纵轴名称
plt.grid(color="gray")- 显示网格
- 网格参数列表
| 参数 | 说明 |
|---|---|
| axis | 默认为'both',可以设置为'x'or'y',让你的网格线垂直于X轴还是Y轴 |
| color | 接受16进制颜色值或指定颜色 |
| linestyle | 线型参考 线型表 |
| linewidth | 表格线宽度,接受整数 |
线型表
| solid | dashed | dashdot | dotted |
|---|---|---|---|
| - | -- | -. | : |
| 实线 | 小段虚线 | 点段虚线 | 点虚线 |
plt.xlim((2,10))- 为这个坐标系设置范围元组
- 有返回值一个元组范围
- ylim同理
plt.xticks(np.linspace(0,5,11)))- 为这个坐标系设置刻度
- 会自己分配间距等等
- 不一定位数越高越精确,找合适的
fig=plt.figure()
ax=fig.add_axes([0.1,0.1,0.8,0.8])
x=np.arange(0.0,5.0,0.2)
y=np.exp(-x) *np.cos(2*np.pi*x)
ax.grid(color='gray')#灰色的网格线
ax.plot(x,y)
ax.set_xlabel("it is x")#设置x轴的标注
ax.set_xlim(-2,10)#设置了x轴范围
#ax.set_ylim(-2,10)
刻度是由短线和短线附近的文本组成的,这些对象都有对应的设置器。
- locator 对象,描述刻度“刻线”,当执行ax.yaxis.set_major_locator(plt.NullLocator())之后,刻线不在在了,即使有“标示”也没有意义了,正所谓“皮之不存,毛将薄附”。
- formater 对象描述刻度的“标示”,所以ax.xaxis.set_major_formatertplt.NullFomater())之后X轴没有了标示,只有刻线了----刻线可以单独存在,类似于刻度尺,在刻度尺上不是每条刻线都有标示。
# 绘制子图
插曲 显示图片
代码我放这里了,我也没搞懂原理:
from sklearn.datasets import fetch_olivetti_faces
faces=fetch_olivetti_faces().images
fig,ax=plt.subplots(5,5,figsize=(5,5))
fig.subplots_adjust(hspace=0,wspace=0)
for i in range(5):
for j in range(5):
ax[i,j].xaxis.set_major_locator(plt.NullLocator())
ax[i,j].yaxis.set_major_locator(plt.NullLocator())
ax[i,j].imshow(faces[10*i+j],cmap="bone")
fig,ax=plt.subplots(2,1,sharex='col',sharey='row')- 0轴方向为2,1轴方向为1生成2x1个坐标系分区
- 返回值有两个,一个是Figure和Axes容器,容器是一个序列对象,里面有好多ax坐标系
- 可以直接取出对象画图ax[0],plot(np.linspace(0,2*np.pi,10),np.sin(np.linspace(0,2 *np.pi,10)))

fig.subplots_adjust(left=None,bottom=None,right=None,wspace=None,hspace=None)- wspace,hspace是分区之间空隙宽和高
#-*-coding:utf-8-*-
#SettingCode here
__author__ = "a_little_rubbish"
__date__ = "2019-04-11 13:27"
#import your model here
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.ticker import MultipleLocator,FormatStrFormatter
t=np.linspace(0,100,100)
s=9.8*np.power(t,2)/2
fig,ax=plt.subplots(figsize=(8,4))
ax.plot(t,s)
ax.set_ylabel("displacement")
ax.set_xlim(0,100)
ax.set_xlabel('time')
xmajor_locator =MultipleLocator(20)#①
xmajor_formatter=FormatStrFormatter('%1.1f')#②
xminor_locator=MultipleLocator(5)
ymajor_locator=MultipleLocator(10000)
ymajor_formatter=FormatStrFormatter('%1.1f')
yminor_locator=MultipleLocator(5000)
ax.xaxis.set_major_locator(xmajor_locator)#③
ax.xaxis.set_major_formatter(xmajor_formatter)#④
ax.yaxis.set_major_locator(ymajor_locator)
ax.yaxis.set_major_formatter(ymajor_formatter)
ax.xaxis.set_minor_locator(xminor_locator)#⑤
ax.yaxis.set_minor_locator(yminor_locator)
ax.grid(True,which='major')
ax.grid(True,which='minor')
for i in ax.xaxis.get_major_ticks():#⑥
i.label1.set_fontsize(16)
plt.show()
fig.savefig('xx.jpg')#保存图片
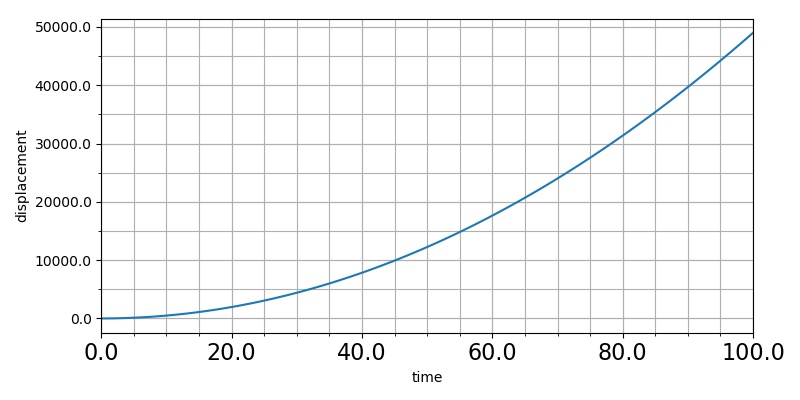
程序的解释:
刻度轴是有主次之分的,from matplotlib.ticker import MultipleLocator,FormatStrFormatter 所引入的 MultipleLocator 类就是用于设置刻度的倍数的
例如①中的含义就是X轴的“主刻线”是20的倍数,即对于程序中,X轴上每20是一个“主刻线”。
FormatStrFormatter用于设置“标示”的显示格式,例如②中规定了“主刻度”的“标示”的显示格式为小数点后要有1位小数。
①和②所建立的对象分别作为参数用于③和④。ax.xaxis得到的是X轴Axes对象,它具有以下两个方法:set_major_locator()设置“主刻线”;set_major_formater()设置相应的“标示”。
⑤中的set_major_locator()设置“次刻线”,因为“次刻线”不需要标示,所以就没有使用set_major_formatter()函数,不过也可以尝试使用。
用同样的方法可以设置Y轴的刻度。
最后,⑥通过循环ax.xaxis.get_major_ticks()得到x轴的主刻度,然后在⑦中对每个主刻度的“标示”字号进行设置,比默认字号大一
plt.subplot(x,y,z....)- 等价于fig.add_subplot()
- 获得分区的某一个子图给plt
- 接下来可以设置plt.text(0.2x,0.5y,str('xxx'),fontsize=18,withdash=False,ha='center',with)文字


画一个小坐标系
fig.add_axes([left,bottom,width,height] left,bottom表示距离画布左侧和底部的距离,width,height表示子图的宽高。这四个值都是取0-1,并表示百分比。 ·
import numpy as np
import matplotlib.pyplot as plt
fig=plt.figure()
ax1=fig.add_axes([0.1,0.1,0.8,0.8])
ax1=fig.add_axes([0.6,0.5,0.2,0.3])
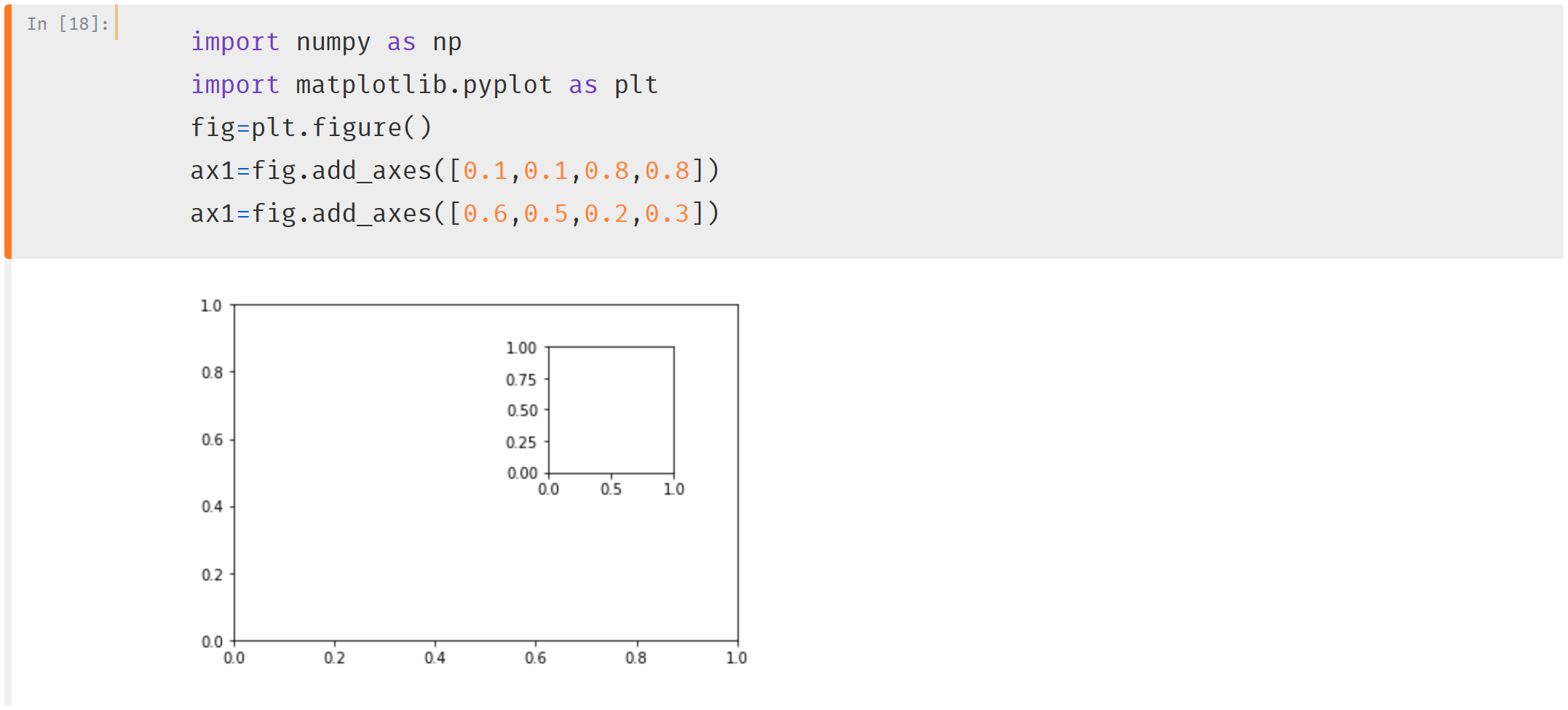
ax.shape可以查看当前的对象容器的序列,通过下标拿到Axes对象可以做一些设置。不使用多个画布分区的时候,可以在同一张画布上有多个坐标系
布局
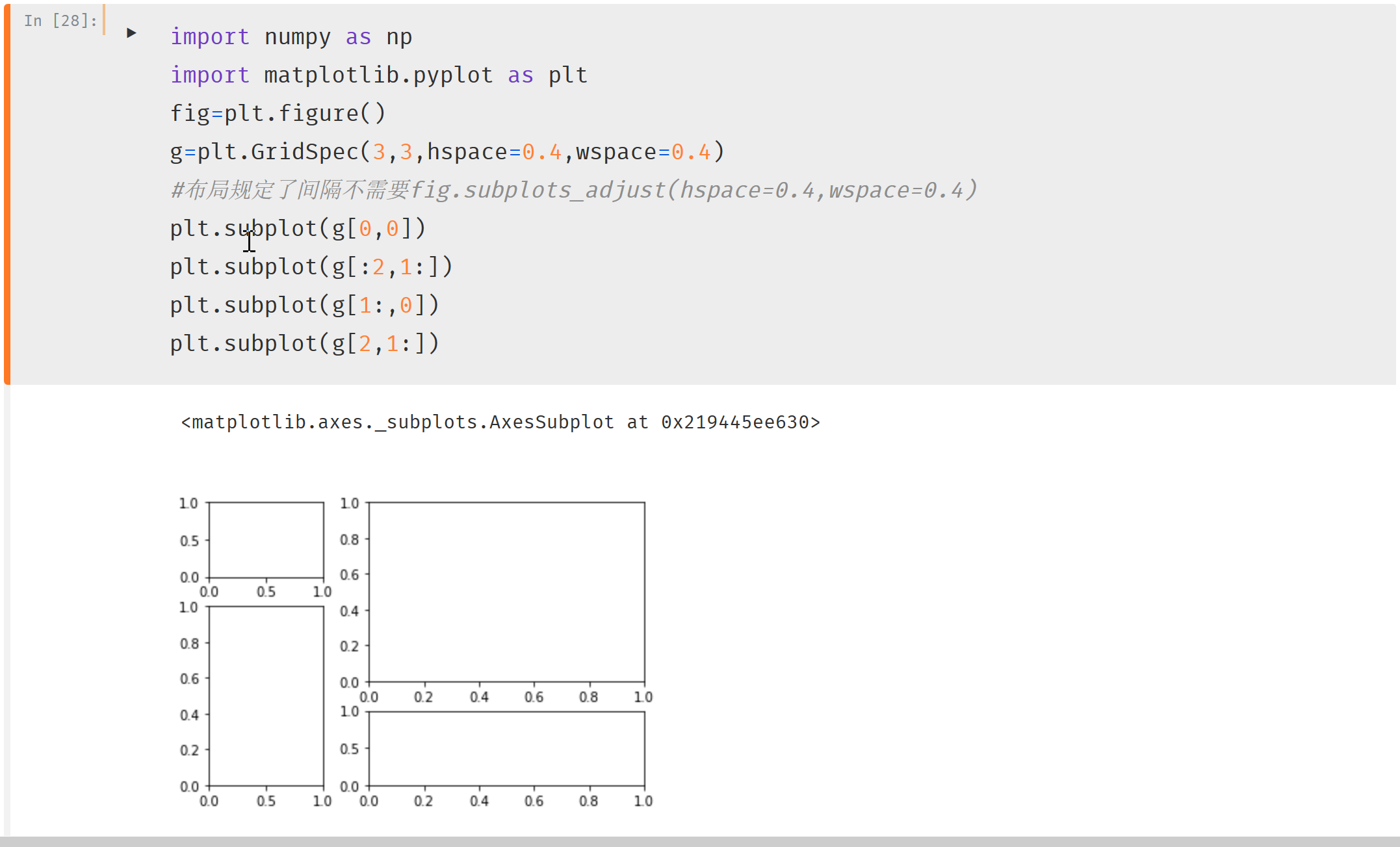
- g=
plt.GridSpec(3,3,hspace=0.3,wspace=0.3)- 划分了3-3等格,间距为0.3,0.3
- 使用plt.subplot(g[n:m])划分区域,见代码
import numpy as np
import matplotlib.pyplot as plt
fig=plt.figure()
g=plt.GridSpec(3,3,hspace=0.4,wspace=0.4)
#布局规定了间隔不需要fig.subplots_adjust(hspace=0.4,wspace=0.4)
plt.subplot(g[0,0])
plt.subplot(g[:2,1:])
plt.subplot(g[1:,0])
plt.subplot(g[2,1:])
# 绘图
plt.plot() or ax.plot() 函数完成
- 颜色,由
color='#A52A2A'参数控制- 1.x版本和2.x(使用的)有改动,2.x变为category10调色板+hex16进制颜色值字符串控制。
- 默认自己填充色彩
- 线型,由
linestyle='dashdot'控制- 参考线型表,默认为实线
- 标注点,由
marker='o'控制- 可选o圆形,D菱形,h六边形
markersize=整数int,标记大小markerfacecolor=''标记颜色markerevery=[1,2,3]在1,2,3处进行标记
- 线粗细,由
linewidth=整数int控制 - 标签
label='起个名吧'- 给曲线一个名字,一般配合legend图例使用
#-*-coding:utf-8-*-
#SettingCode here
__author__ = "a_little_rubbish"
__date__ = "2019-04-11 15:06"
#import your model here
import matplotlib.pyplot as plt
import matplotlib.colors as colors
import matplotlib.cm as cmx
import numpy as np
#your class&function here
curves=[np.random.random(20) for i in range(10)]#随机数组
values=range(10)#随机整数
fig=plt.figure()#产生画布
ax=fig.add_subplot(111)#添加了一个子图??大小参数是怎么回事??只有一个
jet=cm=plt.get_cmap("jet")#获得颜色表
cnorm=colors.Normalize(vmax=values[-1],vmin=0)#也是设置颜色
scalar_map=cmx.ScalarMappable(norm=cnorm,cmap=jet)#画布颜色映射
lines=[]#线数组
for i in range(len(curves)):#数组长度
line=curves[i]#拿到数组
color_val=scalar_map.to_rgba(values[i])#利用颜色表取出颜色
color_text=('color:(%4.2f,%4.2f,%4.2f)'%(color_val[0],color_val[1],color_val[2]))#颜色框上的文本
ret_line,=ax.plot(line,color=color_val,label=color_text)#画上图
lines.append(ret_line)#添加到线数组中去
handles,labels=ax.get_legend_handles_labels()#设置图例
ax.legend(handles,labels,loc='upper right')#放置图例
plt.plot()
plt.show()
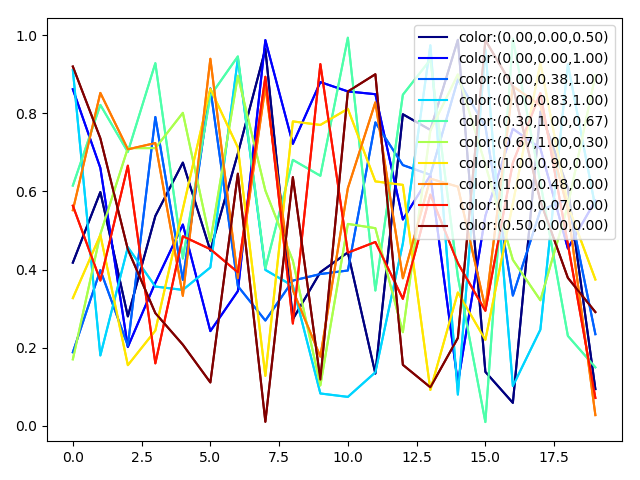
截图2019-04-11_15-53-41.png
import numpy as np
import matplotlib.pyplot as plt
fig=plt.figure()
x=np.random.random(10)#np.random的用法
plt.plot(x,2*x,linestyle=':',marker='o',markersize=9,markerfacecolor='b',markevery=[2,4,6])
x
# 图例
就右上角的小标志那个东西。
plt.legend(loc='upper right') 右上角一个小图例。
loc=""位置- 参照下表,可直接而用编号代替
handle=(line1,line2)给line1和line2画图例bbox_to_anchor=(x0,y0,width,height)把小盒子固定在任意位置- x0,y0是盒子左下角相对于坐标轴左下角的位置0~1的浮点数
- width,height是盒子宽高,也是0~1的浮点数
frameon=fontsize=ncol=framealpha=shadow=fancybox=borderpad=
WARNING
搜一搜这些参数
| 名称 | 编号 | 名称 | 编号 |
|---|---|---|---|
| best | 0 | center left | 6 |
| upper right | 1 | center right | 7 |
| upper left | 2 | lower center | 8 |
| lower left | 3 | upper center | 9 |
| lower right | 4 | center | 10 |
| right | 5 |
import numpy as np
import matplotlib.pyplot as plt
fig=plt.figure()
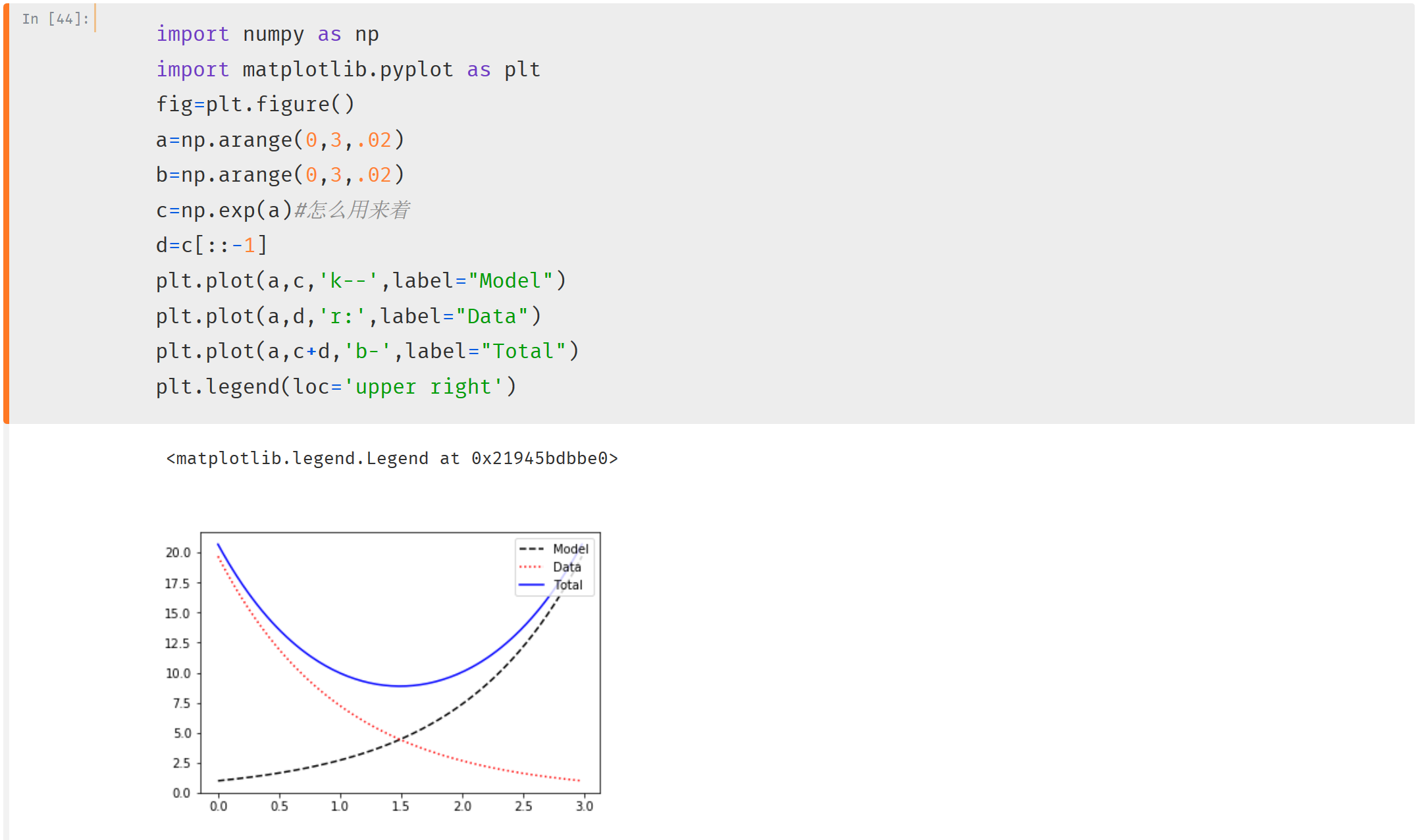
a=np.arange(0,3,.02)
b=np.arange(0,3,.02)
c=np.exp(a)#怎么用来着
d=c[::-1]
plt.plot(a,c,'k--',label="Model")
plt.plot(a,d,'r:',label="Data")
plt.plot(a,c+d,'b-',label="Total")
plt.legend(loc='upper right')
WARNING
plt.plot()返回的是一个列表,注意line1,2,3的返回方式。
有前面的%matplotlib的时候直接省略下面几句,写的时候要注意添加上
TIP
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
fig=plt.figure()
# 散点图
只有一些散点,暂时没有规律的数据
#-*-coding:utf-8-*-
#SettingCode here
__author__ = "a_little_rubbish"
__date__ = "2019-04-11 16:14"
#import your model here
import numpy as np
import matplotlib.pyplot as plt
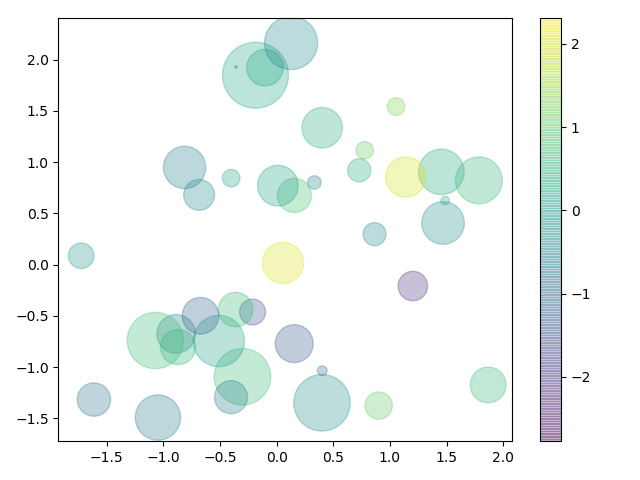
fig=plt.figure()
rng=np.random.RandomState(0)#伪随机数发生器
x=rng.randn(100)#得到符合高斯分布的100个数组成的数组
y=rng.randn(100)
colors=rng.randn(100)
sizes=1000*rng.randn(100)
plt.scatter(x,y,c=colors,s=sizes,alpha=0.3)#透明度颜色
plt.colorbar()#显示颜色条
plt.show()
参数表:
- plt.scatter()
- x,y两个数组,表示点坐标
- s=None点大小默认我也不知道
- marker=None标记,参考标记表
- cmap=None
- norm=None
- vmin=None
- vmax=None
- alpha=None透明度0-1
- linewidths=None边缘线宽度
- verts=None
- edgecolors=None边缘颜色
- hold=None
- data=None
------matplotlib文档
scatter会根据点的大小颜色对每个点进行渲染,各个点不相同,plot不会:(
# 柱形图
普通柱形图
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
fig=plt.figure()
data=[2,10,6,8,7]
position=[i for i in range (1,6)]
plt.bar(x=position,height=data)#这个bar
plt.bar(x=position,height=data,width=0.4,bottom=[3,0,5,0,1])#上面的注释掉再试试这个bar
plt.grid(True)
plt.show()
基本参数:
- x 每根柱子中间所在的坐标位置 [num]
- height 每根柱子的高度 [int]
- width 柱子宽度int
- bottom 柱子底部与坐标轴的距离,默认None等于0 int
- color 颜色可以多种颜色。str
- edgecolor柱边缘颜色str
- linestyle边缘线线型-线型表
- linewidth边缘线宽度int
- hatch填充中间的内部图形str
- tick_label刻度标识,默认数字 [num/str]
 |  |
|---|
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
fig=plt.figure()
data=[2,10,6,8,7]
position=[i for i in range (1,6)]
labels=[i for i in "abcde"]
plt.bar(x=position,height=data,width=0.4,bottom=[3,0,5,0,1],
color='r',edgecolor='#ff7f00',linestyle='--',
linewidth=2,hatch='x',tick_label=labels)
plt.grid(True)
plt.show()
啊奇丑无比的图

堆叠柱状图和簇状
ab两组同维数据,把b设置为
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
fig=plt.figure()
a=[2,10,6,8,7]
b=[3,3,4,9,1]
position=[i for i in range (1,6)]
labels=[i for i in "abcde"]
plt.bar(position,a,label='a',color='b')
plt.bar(position,b,label='b',color='g',bottom=a)#注意这个bottom
plt.legend(loc='upper right')

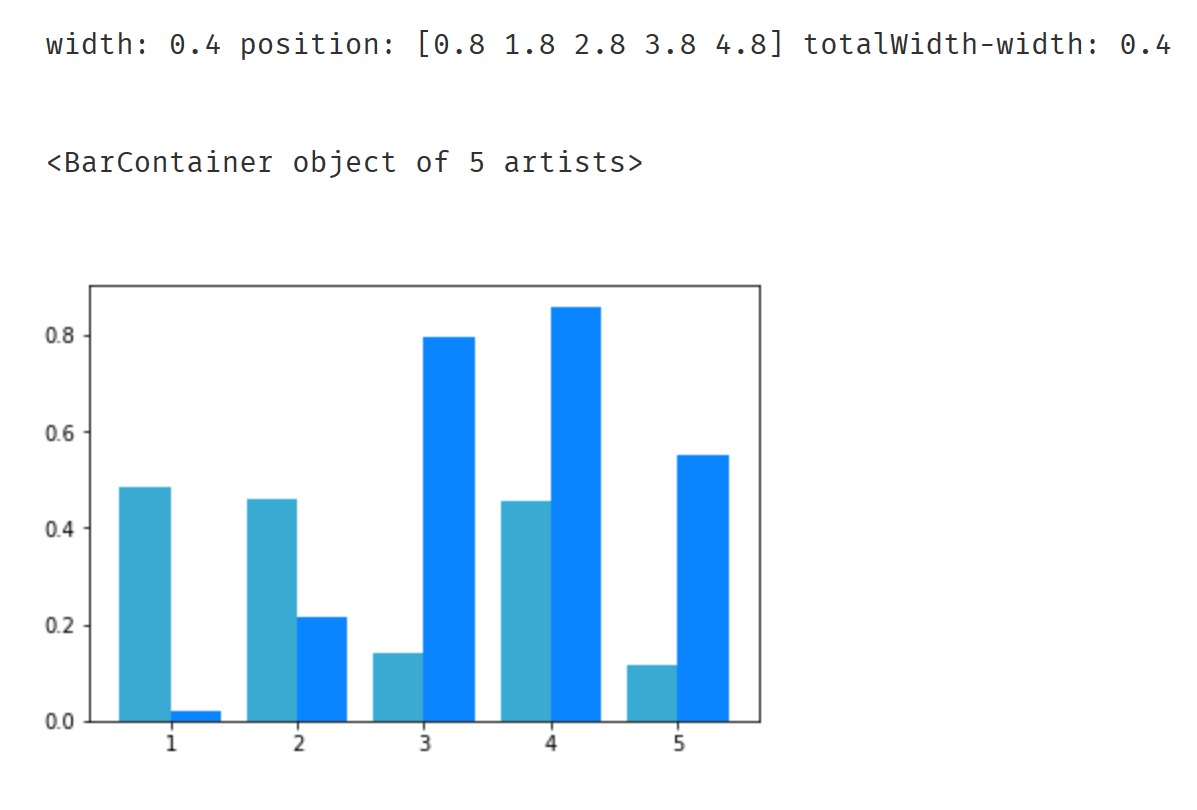
position=np.arange(1,6)
a=np.random.random(5)
b=np.random.random(5)
totalWidth=0.8
n=2
width=totalWidth/n#把宽度分成两半
position=position-(totalWidth-width)/n#
print('width:',width,'position:',position,'totalWidth-width:',totalWidth-width)
plt.bar(position,a,label='a',color='#39abd2',width=width)
plt.bar(position+width,b,label='b',color='#0a84ff',width=width)#注意宽度
颜色好看点了
柱状图差不多了
# 条形图
就是柱状图横过来
position=np.arange(1,6)
a=np.random.random(5)
plt.barh(position,a)

参数和上面的一模一样,拿过来用就是了。
不太一样的是正负柱状图:
position=np.arange(1,6)
a=np.random.random(5)
b=np.random.random(5)
plt.barh(position,a,label='a',color='#ff481f')
plt.barh(position,-b,label='b',color='#05c7da')#注意这里是-b

# 箱线图
一种很有用的图。鉴于笔者懒,就不写那么多了,自己看图吧(~ ̄▽ ̄)~
fig,ax=plt.subplots(1,2)
data=[1,5,9,6]
ax[0].boxplot([data])#注意这个形式
ax[0].grid()
ax[1].boxplot([data],showmeans=True)#显示均值
ax[0].grid()
可以设置vert=True竖过来显示
异常点显示为sym='r*'
meanline=False均值线,但一般中位数常用线段表示,让他默认false就挺好的
简单箱线图,啥都能显示,牛逼不(???
pandas其实也能直接画,不过我会了这个一定不会去学那个的。
装饰挺麻烦的:
#-*-coding:utf-8-*-
#SettingCode here
__author__ = "a_little_rubbish"
__date__ = "2019-04-12 15:45"
#import your model here
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
fig=plt.figure(1,figsize=(9,6))
np.random.seed(123)
d1=np.random.normal(100,10,200)
d2=np.random.normal(80,30,200)
d3=np.random.normal(90,20,200)
d4=np.random.normal(70,25,200)
data=[d1,d2,d3,d4]
ax=fig.add_subplot(111)#fig.add_subplot(1, 1, 1)
bp=ax.boxplot(data,patch_artist=True)
for b in bp['boxes']:
b.set(color='#07718c',linewidth=2)
b.set(facecolor='#2c6ee5')
for w in bp['whiskers']:
w.set(color='#07718c',linewidth=6)
for c in bp['caps']:
c.set(color='#a34ce2', linewidth=2)
for m in bp['medians']:
m.set(color='#dbac3f', linewidth=2)
for f in bp['fliers']:
f.set(color='#2c6ce5', alpha=0.2,marker='^')
plt.show()
# 饼图
饼图其实是很重要的一种统计图。参数如下:
plt.pie
- x 一维的数据源
- explode =None扇面偏离,和x规模一致的数据,在图上显示出来和其他扇面的距离
- labels =None标识和x规模一致的字符串数组
- colors =None 16进制颜色
- autopc t=None 按照规定格式显示百分比例如'%1.1f%%'
- pctdistance =0.6
- shadow =False 阴影
- labeldistance =1.1 标识的距离
- startangle =None 第一个扇形开始的角度
- radius =None 半径大小
- counterclock =True
- wedgeprops =None
- textprops =None
- center =(0,0)
- frame =False
- rotatelabels =False
- hold =None
- data =None
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
fig=plt.figure()
x=[i for i in range(2,10,2)]
print(len(x))
fig,ax=plt.subplots()
labels=['A','B','C',"D"]
colors=[i for i in 'rgby']
explode=[0,0.1,0,0]
plt.pie(x,explode=explode,colors=colors,autopct='%1.1f%%',
shadow=True,startangle=90,radius=1.2)
ax.set(aspect='equal',title='Pie')#注意set的用法,左边有set右边无
 |  |
|---|
# 直方图
柱形图一般是每个柱子单独渲染,然而直方图是一块渲染,因为直方图的数据的部分时候会符合正态分布。
直方图是一种统计报告图,由一个个的长条形组成,但是直方图用长条形的面积表示频数,所以长条形的高度表示频数组距,宽度表示组距,其长度和宽度均有意义。当宽度相同时,一般就用长条形长度表示频数。直方图一般用来描述等距数据,柱状图一般用来描述名称(类别)数据或顺序数据。直观上,直方图各个长条形是衔接在一起的,表示数据间的数学关系;条形图各长条形之间留有空隙,区分不同的类。
plt.hist
- x
- bins=None 这个参数指定柱子的个数,也就是总共有几条条状图
- range=None =(x,y)筛选数据范围,默认是最小到最大的取值范围
- density=None 设置为True是频率图,默认是频数图
- normed=None 已被density替代
- weights=None
- cumulative=False 设置为True会把前面的值都累加起来
- bottom=None 可以像柱状图一样叠加
- histtype='bar' 柱主子类型bar, barstacked, step, stepfilled
- align='mid' 对齐方式,一般都是居中
- orientation='vertical' 水平或垂直方向显示
- rwidth=None 柱子与柱子之间的距离,默认是0
- log=False
- color=None 直方图16进制颜色
- edgecolor 直方图边框颜色
- label=None 标签
- stacked=False
- hold=None
- data=None
左图:
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
# 谁便生成一堆数据
mu = 100 # 均值
sigma = 15 # 标准差
x = mu + sigma * np.random.randn(10000)
num_bins = 50
# the histogram of the data
n, bins, patches = plt.hist(x, num_bins, density=1, color='blue', alpha=0.5)
# 添加正态分布曲线(这个很好看
y = mlab.normpdf(bins, mu, sigma)
plt.plot(bins, y, 'r--')
plt.xlabel('Smarts')
plt.ylabel('Probability')
plt.title(r'Histogram of IQ: $\mu=100$, $\sigma=15$')
# Tweak spacing to prevent clipping of ylabel
plt.subplots_adjust(left=0.15)
plt.show()
注意添加曲线的那一步
右图
import matplotlib.pyplot as plt
#概率分布直方图
#正态分布
mean = 100 #均值为100
sigma = 1 #标准差为1
x=mean+sigma*np.random.randn(10000)
fig,(ax0,ax1) = plt.subplots(nrows=2,figsize=(9,6)) #产生俩画布
ax0.hist(x,100,density=1,color='yellowgreen',alpha=0.75) #第二个参数是柱子宽一些还是窄一些,越大越窄越密
##pdf概率分布图,一万个数落在某个区间内的数有多少个
ax0.set_title('pdf')
ax1.hist(x,20,density=1,color='pink',alpha=0.75,cumulative=True,rwidth=0.8)
#cdf累计概率函数,cumulative累计。比如需要统计小于5的数的概率
ax1.set_title("cdf")
fig.subplots_adjust(hspace=0.4)
plt.show()
 |  |
|---|
# 三维曲线图
三维目前还不常用,用到去查ax.plot3D?
三维坐标还蛮好看的,接收到ax对象之后画图之前from mpl_toolkits import mplot3d,设置ax=plt.axes(projection='3d')
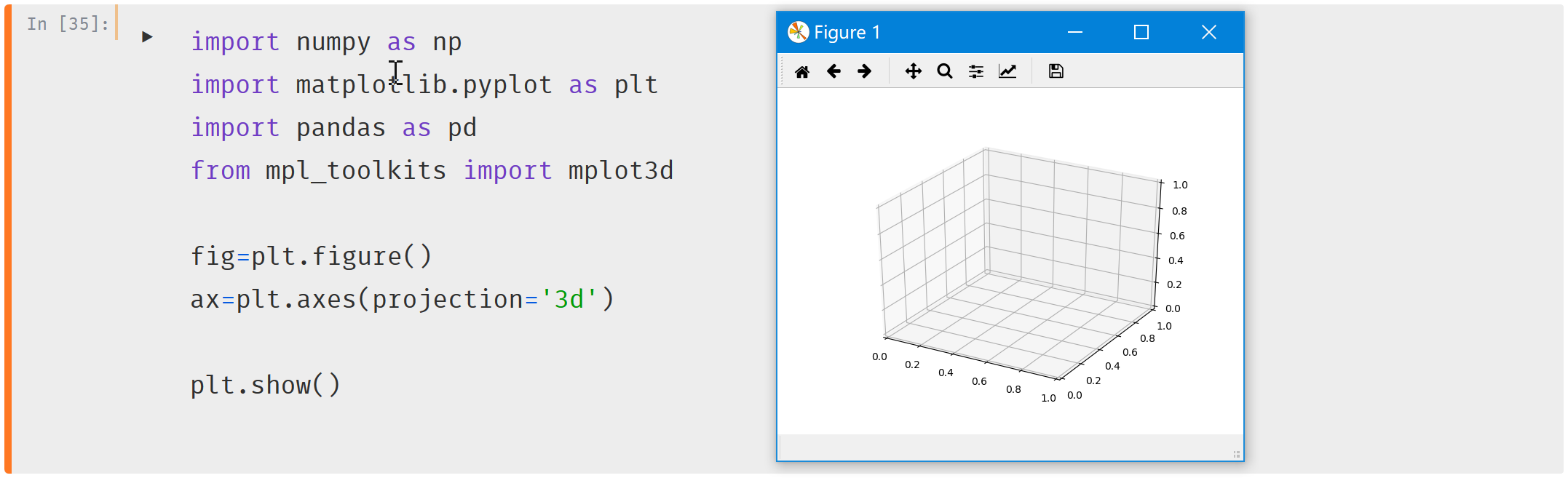
曲线和散点图分别用ax.plot3D和ax.scatter3D()
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from mpl_toolkits import mplot3d
fig=plt.figure()
ax=plt.axes(projection='3d')
xl=np.linspace(0,5,1000)#linespace咋用来着
yl=np.sin(xl)#s普通的sin cos啥效果
zl=np.cos(xl)
ax.plot3D(xl,yl,zl,color='b')
xp=15*np.random.random(100)
yp=np.sin(xp)+0.1*np.random.random(100)
zp=np.cos(xp)+0.1*np.random.random(100)
ax.scatter3D(xp,yp,zp,c=xp,cmap="Greens")#后面的俩参数是啥
plt.show()
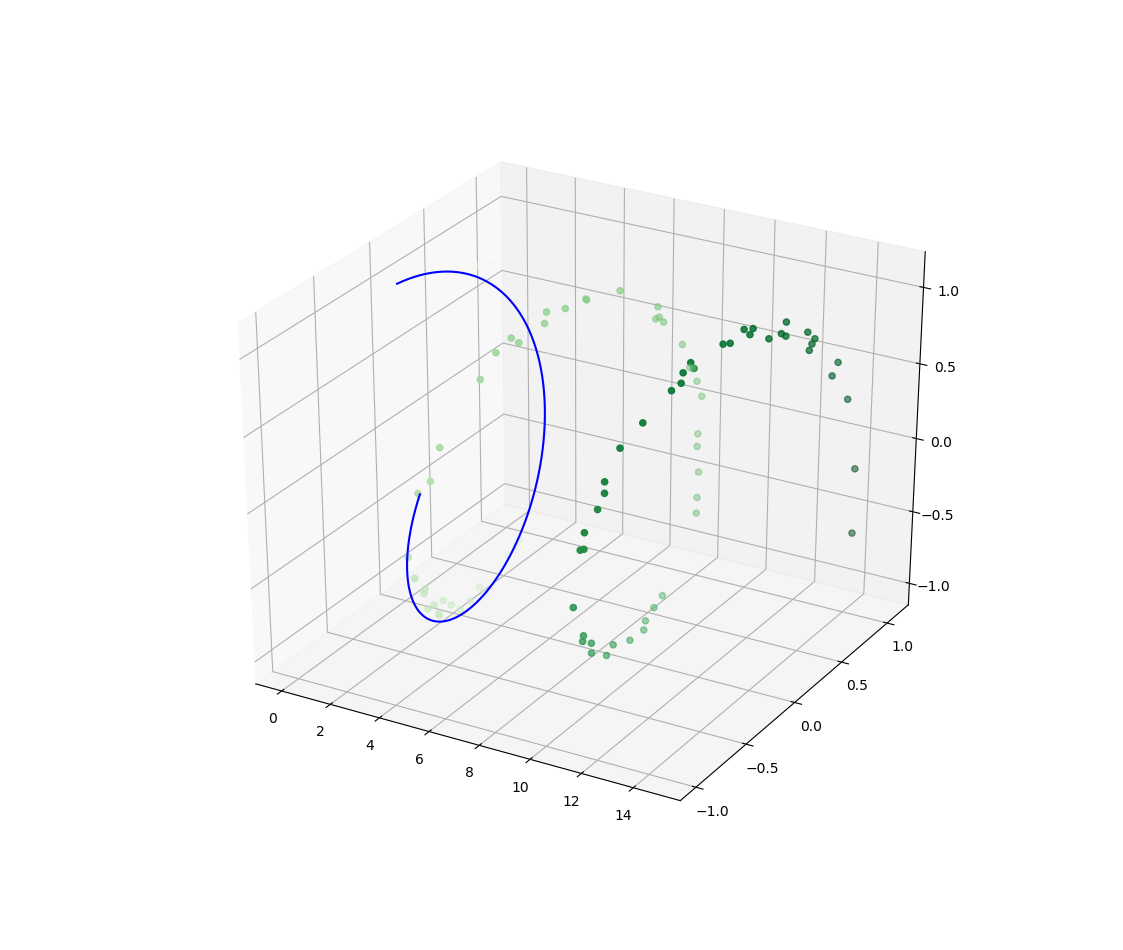
# 三维等高线图
卧槽好他妈炫酷Σ(っ °Д °;)っ
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from mpl_toolkits import mplot3d
x=np.linspace(-6,6,30)
y=np.linspace(-6,6,30)
X,Y=np.meshgrid(x,y)
Z=np.sin(np.sqrt(X**2+Y**2))
fig=plt.figure()
ax=plt.axes(projection='3d')
ax.contour3D(X,Y,Z,50,cmap='binary')#哪个50是啥,后面cmap肯定是管颜色的
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax.view_init(60,35)
后面还有莫比乌斯环结构网三角形,太偏门了,先把这些用好了再说.用到去查文档
其他很多图等用到再去查:
- 绘制平行于X轴的直线—pltaxhline()
- 绘制平行于Y轴的直线—plt.axvline()
- 绘制平行于X轴的区间带plt.axhspan()
- 绘制平行于Y轴的区间带—plt.axvspan()
- 绘制梯状图—plt.step()
- 绘制小提琴图—plt.violinplot()
- 绘制误差图—plt.errorbar()
- 绘制填充图——plt.fill_between()
------跟老齐学数据分析
# 数据领域的Github---plotly
链接这个网站专门做图表可视化的。进入注册登录傻子都会我就不写了。进入setting 点击APIkeys->Regenerate Keys。然后你就得到了这个k和你的用户名
然后pip install plotly
在jupyter/py程序中
import plotly
plotly.tools.set_credentials_file(username='xxx',api_key='xxxxxxxxxxx')
#画一个例子
import plotly.plotly as py
datas=np.random.rand(1000)
plt.hist(datas)
fig=plt.gcf()
plot_url=py.plot_mpl(fig,filename='my-chart')
运行就会蹦出一个网页
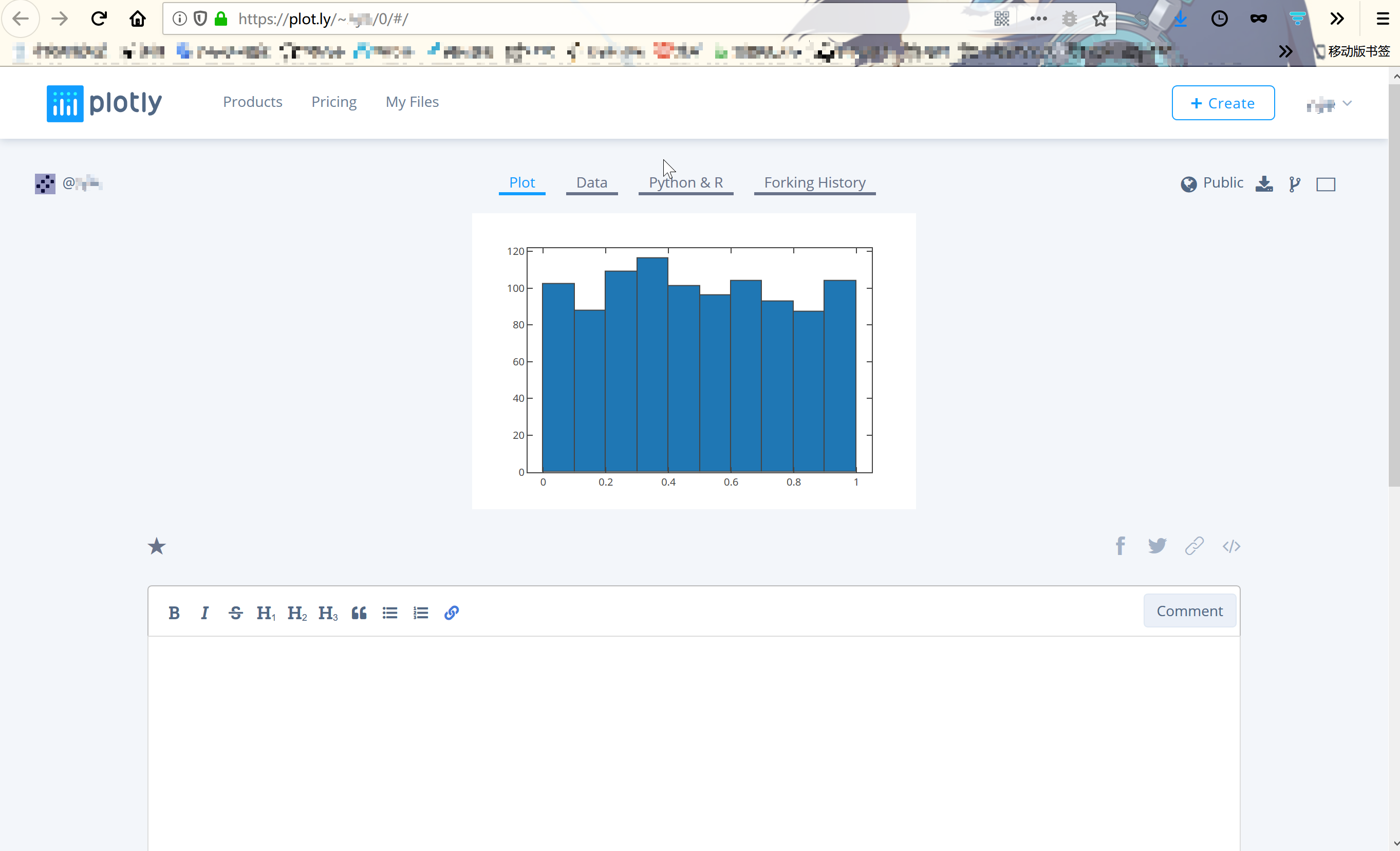
这样你就可以和全世界分享你做的图勒。放个我做的
# seaborn
说实话我觉得matplotlib挺丑的(别打我( ﹁ ﹁ )可能是我画的丑。seaborn就好看了许多
import seaborn as sns现在的matplotlib还属主流,seaborn稍微一看几个图,了解基本的规律即可,不会就去查文档
import pandas as pd # Pandas
import numpy as np # Numpy
import matplotlib.pyplot as plt # Matplotlibrary
import seaborn as sns # Seaborn Library
%matplotlib inline
sns.set()
jupyter头上输入这个相当于每个块都输入了这个,而且定义的变量可以混用了
看一下数据集
tips = sns.load_dataset("tips")#内置的数据集
type(tips)#pandas.core.frame.DataFrame这货是个pandas
tips.head(4)#默认查看前五条,记住这个方法
# 样式控制
seaborn的样式控制是个变化较大的地方,集中了起来而不是分散的样式
第一组是设置绘图的外观风格的,第二组主要将绘图的各种元素按比例缩放的,以至可以嵌入到不同的背景环境中。
操控这些参数的接口主要有两对方法:
- 控制主题:
- sns.axes_style()
- sns.set_style('darkgrid')
- 缩放绘图:
- sns.plotting_context()
- sns.set_context()
这两个的第一个方法都会返回一组字典参数,而第二个方法会设置matplotlib的默认参数。
内置五种seaborn的风格:darkgrid, whitegrid, dark, white, ticks
可以自定义主题sns.axes_style()
{'axes.facecolor': '#EAEAF2',
'axes.edgecolor': 'white',
'axes.grid': True,
'axes.axisbelow': True,
'axes.labelcolor': '.15',
'figure.facecolor': (1, 1, 1, 0),
'grid.color': 'white',
'grid.linestyle': '-',
'text.color': '.15',
'xtick.color': '.15',
'ytick.color': '.15',
'xtick.direction': 'out',
'ytick.direction': 'out',
'lines.solid_capstyle': 'round',
'patch.edgecolor': 'w',
'image.cmap': 'rocket',
'font.family': ['sans-serif'],
'font.sans-serif': ['Arial',
'DejaVu Sans',
'Liberation Sans',
'Bitstream Vera Sans',
'sans-serif'],
'patch.force_edgecolor': True,
'xtick.bottom': False,
'xtick.top': False,
'ytick.left': False,
'ytick.right': False,
'axes.spines.left': True,
'axes.spines.bottom': True,
'axes.spines.right': True,
'axes.spines.top': True}
sns.set_style("darkgrid", {"axes.facecolor": ".9"})像这样就自定义了一些参数
绘图之前设置一下即可
sns.despine()可以移除上面和右面的坐标线
- left,right, bottom,top 让其=True移除左右上下的线
- trim=False 设置True之后限制已有的坐标范围??
- offset=int 设置坐标的偏移
# 柱状图
参数基本和matplotlib的plot差不多
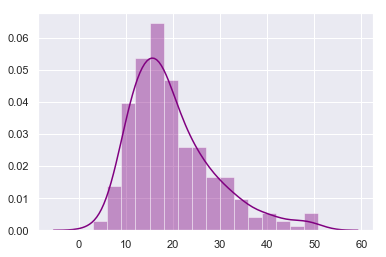
sns.distplot(tips["total_bill"], bins=16, color="purple")
# 联合分布图
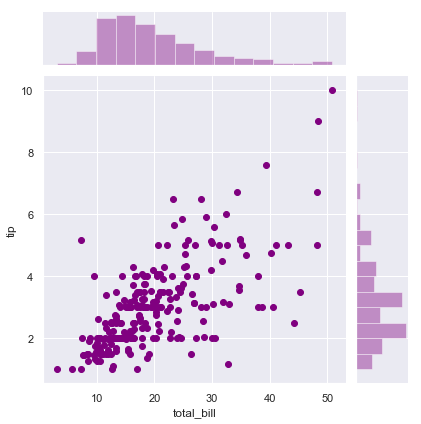
联合分布图 (Jointplot)采用两个变量并一起创建直方图和散点图。
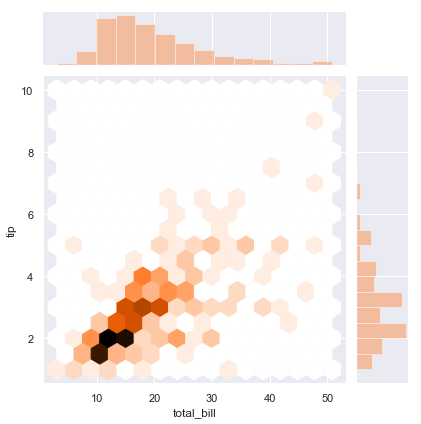
sns.jointplot(x = tips["total_bill"], y = tips["tip"], color="purple")
sns.jointplot(x = "total_bill", y = tips"tip", data=tips,color="purple",kind ="hex")
效果是相等的上面两句,样式第二个选择了hex(scatter | reg | resid | kde | hex),注意DateFrame的运用,参数和plot里面控制样式的参数差不多,主要是数据传入
 |  |
|---|
# 数组对比图
sns.pairplot(data=tips,hue='sex')
传入的是一个dataframe,指定一个数据字段,画出属性分布,对比,直方分布等等,贼全面。
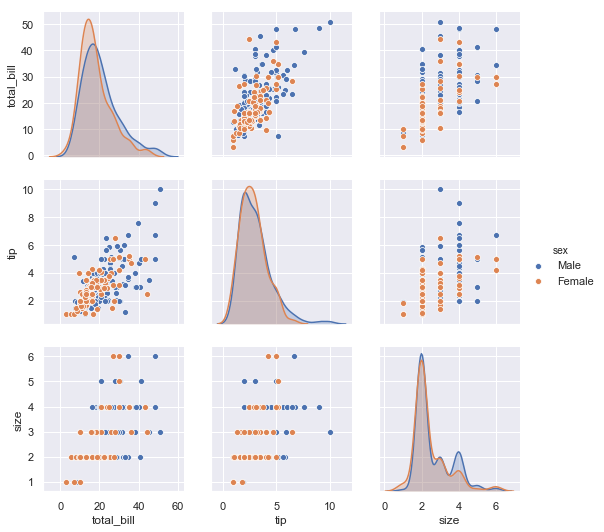
着重看一下参数: data
- hue=None按照哪个属性分割
- hue_order=None排序方式,用到再说
- palette=None控制颜色的东西例如“Set2”颜色系列
- vars=None[需要参与进去的属性列表,可以自己控制让一些属性不参与]
- x_vars=None和上面差不多,一般不用管
- y_vars=None和上面差不多,一般不用管
- kind='scatter'图类型
scatterorreg - diag_kind='auto'
- markers=None标记,可以是matplotlib标记中的一种,也可以是个数组
- height=2.5高度
- aspect=1
- dropna=True
- plot_kws=None
- diag_kws=None
- grid_kws=None
- size=None
# 柱状图
sns.barplot(x = "day", y = "total_bill", data =tips)
参数还是一样的,但是默认样式已经变了,好看了许多

# 小提琴图
sns.violinplot(x = "day", y = "total_bill", data = tips)
和箱线图差不多
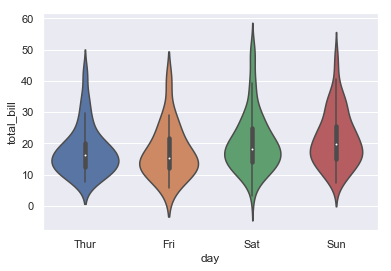
如果x轴是分类的并且y轴是连续的,则应创建箱线图或小提琴图
# 箱线图
sns.boxplot(x = "day", y = "total_bill", data=tips)
注意hue参数
sns.boxplot(x = "day", y = "total_bill", data=tips, hue = "smoker")
 |  |
|---|
# 线性回归图
sns.lmplot(x = "total_bill", y = "tip", data = tips, hue="day")
这个图会显示变量之间的线性回归关系。
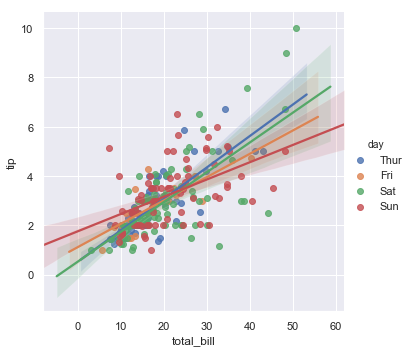
TIP
seaborn封装了matpoltlib,参数都差不多,jupyter里面调一下help?啥都有不会的现查也一点不费劲
# Scipy
这是干嘛用的┑( ̄Д  ̄)┍
好像是个科学计算库,还挺高级的
哦哦看完前面的再说吧